SQL-Powered Reading List
2022-03-08
I have some items burning a hole on my to-do list, so instead I made my reading list queryable via SQL.
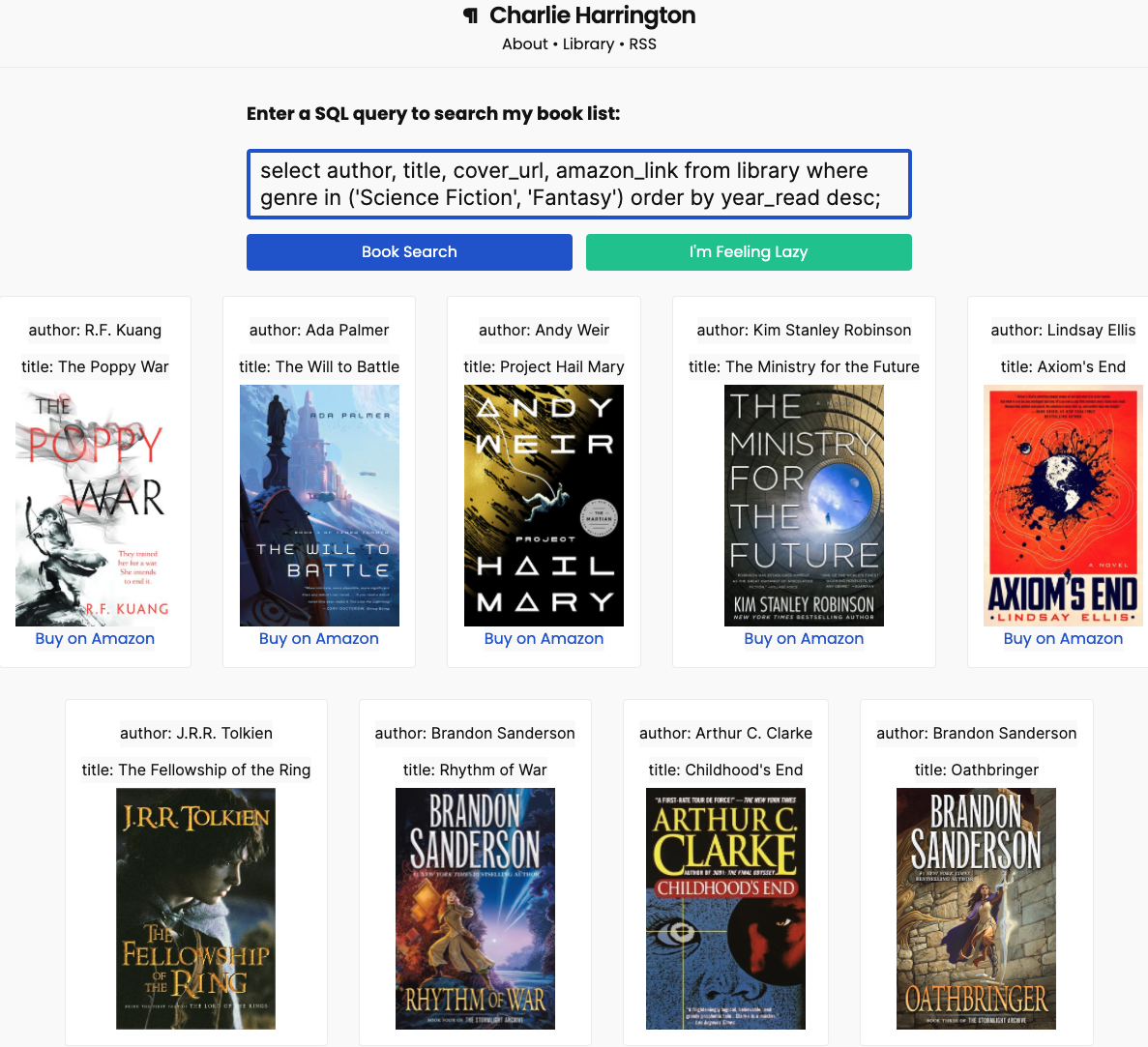
Hit the I'm Feeling Lazy button if you're not feeling especially structured in your queries.
What's going on here, exactly?
I keep my reading list in a Google Sheet. Here's what I looks like (...it's just a spreadsheet).
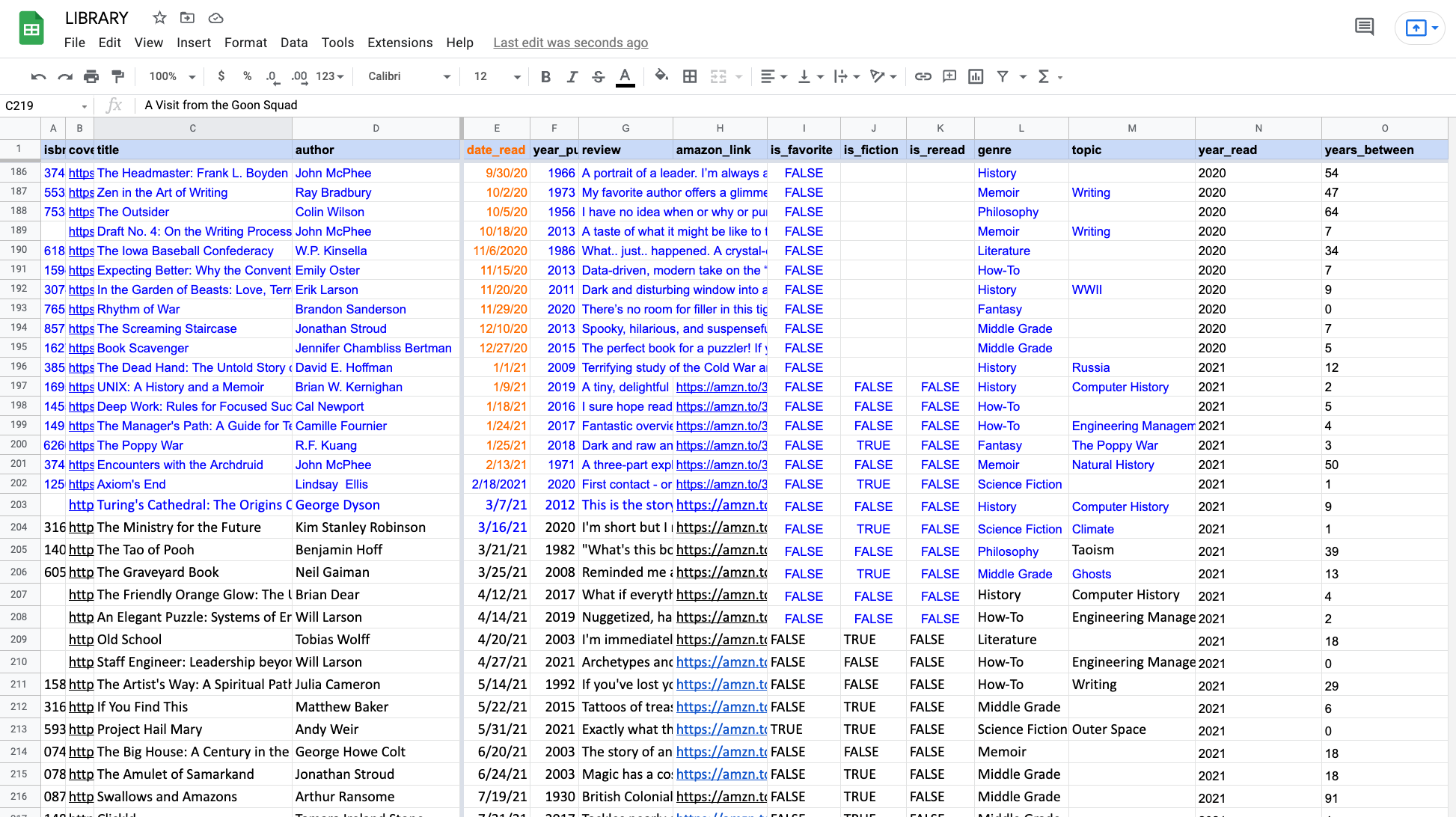
For a while, I was relying heavily on Goodreads for my reading data, but now I'm doing my best to live up to Tom MacWrite's Indie Bookshelves guidance, though, like he suggests, I'd ideally love to have some sort of POSSE (Publish (on your) Own Site, Syndicate Elsewhere) setup going.
As you may have noticed (if you squinted), I'm still behind in inputting all of my "data" (the is_fiction and is_reread columns are still not fully populated). Also adding new entries is still painfully manual, which needs further thinking.
But - the key thing here - this reading list is already good/useful enough for an experimental library feature!
ROAPI
My friend QP is a genius and the best programmer I know (hi, QP!). One of his most recent projects is called ROAPI (read-only API). Here's how he describes it:
ROAPI automatically spins up read-only APIs for static datasets without requiring you to write a single line of code. It builds on top of Apache Arrow and Datafusion. The core of its design can be boiled down to the following:
* Query frontends to translate SQL, GraphQL and REST API queries into Datafusion plans.
* Datafusion for query plan execution.
* Data layer to load datasets from a variety of sources and formats with automatic schema inference.
* Response encoding layer to serialize intermediate Arrow record batch into various formats requested by client.
He even made a diagram:

I've been looking for excuses to use ROAPI (I even started learning Rust this month so that I could help contribute to the project. So far, I've made a few measly PRs to ROAPI, but I also got distracted by learning how to make a Dungeon Crawler 2D game in Rust - which you can even play online via WASM!).
ROAPI already supports Google Sheets as a datasource, so this tutorial is pretty much already done. The magic of ROAPI is that there's no bespoke code I need to write - all I need to do is set up its config file to point to my Google spreadsheet and I've got a fast API server that can perform bi-directional communication in JSON, SQL, or GraphQL. Which is insanely cool.
I just needed somewhere to host ROAPI. QP provides a pre-built Docker image as well as via a Python package. My first thought was to host on a free Heroku dyno, but I had some trouble getting their dynamic PORT env variable to work correctly (despite me adding support in ROAPI to set the PORT via env vars, which I tested and confirmed works! Oh, well.)
My next idea was to do something I'd been meaning to do for a while - check out Replit's "always-on" REPL mode.
Replit
I've written before about my love for Replit.
Here's how I got my ROAPI setup on Replit
- Create a Python repl (make it Private, so you need to be on their $7/month Hacker plan)
- Install "roapi-http" in packages tab
- Create a file: "roapi.yaml" with these contents
tables:
- name: "library"
uri: "https://docs.google.com/spreadsheets/d/1FCKSd4GBZIOe-bQG7k7Y3oA_MqMrxEx0QDzdkrkzIgI/edit"
option:
format: "google_spreadsheet"
application_secret_path: "ohsheet.json"
- Create another file called "ohsheet.json" (or whatever you put in your config file) with your Google Sheets creds (remember this REPL needs to be private). Follow QP's Google Sheets guide in the ROAPI docs for instructions of how to get these creds. Feature request for Replit: it would be nice if there were a (hacky) way to read Replit's "Secrets" (env vars) in a YAML file, so that I didn't have to do this.
- Update "main.py" with these contents:
import subprocess
import os
my_env = os.environ.copy()
my_env["HOST"] = "0.0.0.0"
process = subprocess.Popen(
[
'roapi-http',
'-c',
'./roapi.yml'
],
env=my_env,
stdout=subprocess.PIPE,
universal_newlines=True,
)
while True:
output = process.stdout.readline()
print(output.strip())
return_code = process.poll()
if return_code is not None:
print('RETURN CODE', return_code)
for output in process.stdout.readlines():
print(output.strip())
break
- Hit Run at the top and we're done! I can see my logs in the bottom right corner for any incoming requests. Replit's like being able to SSH into your API server and make random changes at will - dangerous AND fun!
My API is public, so anyone can give this a shot in their terminal (why not try out the GraphQL endpoint?):
curl -X POST -d "query { library(limit: 10) {title, amazon_link, author, is_favorite} }" https://roapi-library.whatrocks.repl.co/api/graphql
[{"title":"Heir to the Empire","amazon_link":"https://amzn.to/3r38doD","author":"Timothy Zahn","is_favorite":false},{"title":"Dark Force Rising","amazon_link":"https://amzn.to/3pXfpkE","author":"Timothy Zahn","is_favorite":false},{"title":"The Making of Prince of Persia","amazon_link":"https://amzn.to/2Pcc7gE","author":"Jordan Mechner","is_favorite":false},{"title":"Butcher's Crossing","amazon_link":"https://amzn.to/3kvbGtz","author":"John Williams","is_favorite":true},{"title":"Surely You're Joking, Mr. Feynman!: Adventures of a Curious Character","amazon_link":"https://amzn.to/2MxqkUu","author":"Richard P. Feynman","is_favorite":false},{"title":"This Boy's Life","amazon_link":"https://amzn.to/3r8gqru","author":"Tobias Wolff","is_favorite":true},{"title":"The Once and Future King","amazon_link":"https://amzn.to/2NErKgH","author":"T.H. White","is_favorite":false},{"title":"The Knight","amazon_link":"https://amzn.to/3bLgUNH","author":"Gene Wolfe","is_favorite":false},{"title":"Birds Without Wings","amazon_link":"https://amzn.to/3r5oQQi","author":"Louis de Bernières","is_favorite":false},{"title":"Cryptonomicon","amazon_link":"https://amzn.to/2O402cV","author":"Neal Stephenson","is_favorite":false}]
I have no idea what happens if this endpoint gets hammered. Maybe Replit just turns it off? Regardless, I enabled their "Always On" feature, as well as "Boosted" which gives my REPL some extra compute juice.
No, 'drop table library' does not work
Cause it's "read only", remember?
My library is up and running and you can try it out now. I even added a consistent query param with the SQL query so that I could share links to books about Writing or my favorite books about ancient Rome, for example. I used a bunch of "vanilla JS" to make this work, given that my blog is a static site built with Syte / EJS, so there was a lot of googling for XMLHTTPRequest docs.
Some things I'm going to think about more, next time I'm procrastinating:
- Automatically trigger daily restarts of the REPL so that I can get an updates to the spreadsheet (ROAPI does not yet dynamically re-load contents, it only does so one time, at the beginning)
- Finish up adding the remaining fields/data to the spreadsheet, maybe while re-watching Halt and Catch Fire.
- I can't seem to get doubly-nested
group bySQL queries working, maybe I can look into this on the ROAPI side - Add WASM support to ROAPI so that I don't need a server at all